
Data stacking is a data preparation step where a data set is split into subsets, and the subsets are merged by case (or stacked on top of one another). The number of variables in the data decreases, and the number of cases increases. This is sometimes referred to as converting data from a wide format to a long format.
This article describes how to stack a data set in Q. There are two approaches that you can take:
- Use Tools > Stack SPSS .sav File. This gives you a drag-and-drop interface to organize your variables and save a new SPSS File.
- Import your data using File > Data Sets > Add > R. Q’s integration with R allows you to write code to pre-process your data during the importation step.
A worked example
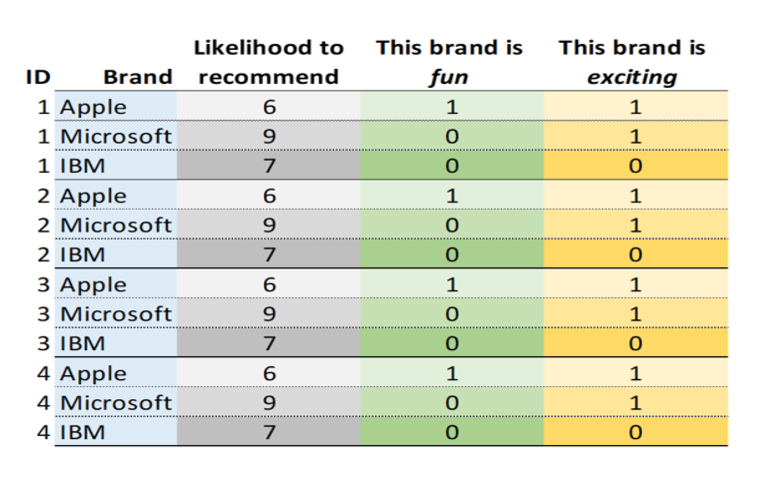
In this article we consider data from a simple survey which asked people about how they rate different technology brands. You can try this example for yourself by downloading the data file here, or by using the code below. I’ve shown a subset of the data before and after stacking, below.

Before stacking, you should always look at your data and work out:
- Which variables do you want to stack?
- Which variable is the ID variable?
- Are there other variables in your data you want to include but not stack? These will be stretched, which means that their values will be repeated several times for each of the original cases.
- Which variables do you want to exclude from the new data?
Stacking data in Q using drag and drop
To stack the data in Q using drag and drop:
- If the initial file is not an SPSS data file, do the following, else skip to step 3:
- Import it into Q (File > Data Sets > Add to Project).
- Convert it into an SPSS data file: Tools > Save Data as SPSS/CSV file.
- Start a new Q project: File > New Project.
- Add the SPSS data file to the project: File > Data Sets > Add to Project > From File, select the file, and press Open.
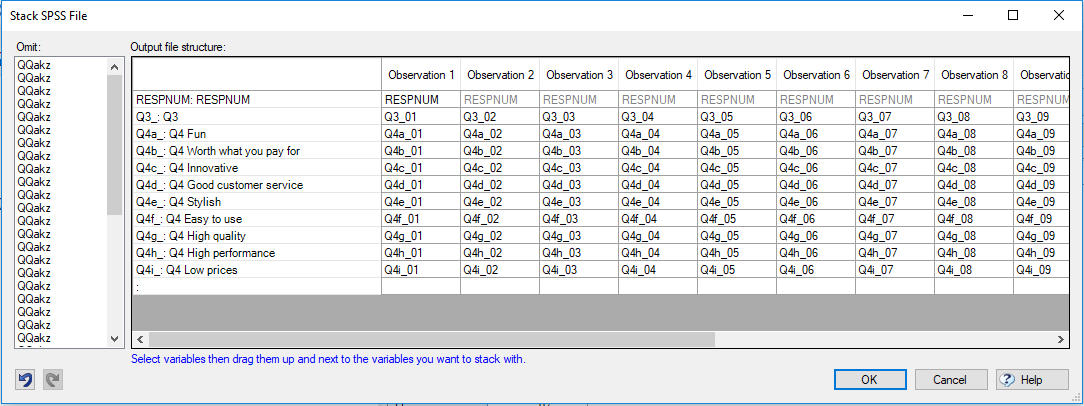
- Select Tools > Stack SPSS .sav File to open the drag-and-drop stacking interface.
- Arrange your stacked variables so that the first variable from each set is placed under the column Observation 1, the second variable from each set falls under the column Observation 2, and so on. The most efficient way to do this is to drag multiple variables at once. In our example this is as follows. For each set of stacked variables:
- Locate the first variable in the set, for example Q3_01
- Highlight all of the other variables which you want to stack on top of that variable. For example, Q3_02 to Q3_13.
- Click and drag them to the right of the first variable, so that their names appear in columns for Observation 2, Observation 3, etc.

6. Drag any variables that you don’t want to include in the stacked file over in to the Omit section on the left. In our example we have omitted “Observation 14” as this pertains to a “None of these” response, rather than an actual brand. It is worth keeping an ID variable such as RESPNUM as a case identifier, and/or if you want to create relationships between datafiles.
7. Press OK. Choose an appropriate file name and location, and press Save.
8. Add the new data file to the project: File > Data Sets > Add to Project > From File, select the file, and press Open.
9. Go to the Variables and Questions tab for the new file, and select the observation variable (probably at the bottom of the file) and press the … button (in the middle of the screen):
- Enter the Label for each value (e.g., if the first variable was Apple, and the second was Microsoft, then enter these in the first two rows).
- Check the Missing Data option for any categories you want to exclude, such as None of these.
- Press OK.
- Change the Label for observation to Brand (or whatever the distinct observations represent in your study).
See the Q wiki for more information about stacking by drag and drop.
Stacking data in Q using code
To stack data in Q using R code, select File > Data Sets > Add to Project > From R and enter in the R code below. The code below first imports the data and then stacks it. Press the update button (►), give the data set a Name, and press Add Dataset. You will need to change the labels on the brand variables (as per step 10 above).
# Reading in the data
library(foreign)
tech = suppressWarnings(read.spss("https://www.qresearchsoftware.com/wp-content/uploads/Technology_2018-1.sav",
use.value.labels = TRUE,
to.data.frame = TRUE))
# Stacking the data
id.variable = 'RESPNUM'
variables.to.stretch = c('Q1', 'Rec_Age')
variables.to.stack = list(
'Recommend' = c('Q3_01', 'Q3_02', 'Q3_03', 'Q3_04', 'Q3_05',
'Q3_06','Q3_07','Q3_08','Q3_09','Q3_10','Q3_11',
'Q3_12','Q3_13'),
'Fun' = c('Q4a_01','Q4a_02','Q4a_03','Q4a_04','Q4a_05','Q4a_06',
'Q4a_07','Q4a_08','Q4a_09','Q4a_10','Q4a_11','Q4a_12','Q4a_13'),
'Worth what you pay for' = c('Q4b_01','Q4b_02','Q4b_03','Q4b_04','Q4b_05','Q4b_06',
'Q4b_07','Q4b_08','Q4b_09','Q4b_10','Q4b_11','Q4b_12','Q4b_13'),
'Innovative' = c('Q4c_01','Q4c_02','Q4c_03','Q4c_04','Q4c_05','Q4c_06',
'Q4c_07','Q4c_08','Q4c_09','Q4c_10','Q4c_11','Q4c_12','Q4c_13'),
'Good customer service' = c('Q4d_01','Q4d_02','Q4d_03','Q4d_04','Q4d_05','Q4d_06',
'Q4d_07','Q4d_08','Q4d_09','Q4d_10','Q4d_11','Q4d_12','Q4d_13'),
'Stylish' = c('Q4e_01','Q4e_02','Q4e_03','Q4e_04','Q4e_05','Q4e_06',
'Q4e_07','Q4e_08','Q4e_09','Q4e_10','Q4e_11','Q4e_12','Q4e_13'),
'Easy-to-use' = c('Q4f_01','Q4f_02','Q4f_03','Q4f_04','Q4f_05','Q4f_06',
'Q4f_07','Q4f_08','Q4f_09','Q4f_10','Q4f_11','Q4f_12','Q4f_13'),
'High quality' = c('Q4g_01','Q4g_02','Q4g_03','Q4g_04','Q4g_05','Q4g_06',
'Q4g_07','Q4g_08','Q4g_09','Q4g_10','Q4g_11','Q4g_12','Q4g_13'),
'High performance' = c('Q4h_01','Q4h_02','Q4h_03','Q4h_04','Q4h_05','Q4h_06',
'Q4h_07','Q4h_08','Q4h_09','Q4h_10','Q4h_11','Q4h_12','Q4h_13'),
'Low prices' = c('Q4i_01','Q4i_02','Q4i_03','Q4i_04','Q4i_05','Q4i_06',
'Q4i_07','Q4i_08','Q4i_09','Q4i_10','Q4i_11','Q4i_12','Q4i_13'))
all.names = names(tech)
variables.to.exclude = all.names[!all.names %in% c(unlist(variables.to.stack), id.variable, variables.to.stretch)]
stacked.tech = reshape(data = tech,
idvar = id.variable, direction = "long",
drop = variables.to.exclude,
varying = variables.to.stack)
names(stacked.tech) = c(id.variable, variables.to.stretch, "brand", names(variables.to.stack))
stacked.tech
This code:
- Imports the data file from a URL and converts it to a data frame using the function spss from the package foreign.
- Specifies the ID variable (variable) and variables which are to be stretched (variables.to.stretch).
- Specifies the groups of variables to be stacked (to.stack). Each element of the list is given a name which identifies the meaning of the stacked variable, and each set of variables is set out in the order in which they are to be stacked.
- Works out which variables are remaining and should be excluded (to.exclude).
- Applies the reshape function to perform the stacking.
- Tidies the column names of the reshaped file in the final line.


